Какая я по характеру тест: Тест на характер: какой ты человек? PEOPLETALK
Содержание
Тесты личности и характера
Категория
- Все тесты
- Личность и характер
- Темперамент
- Межличностные отношения
- Диагностика отклонений
- Депрессия и стресс
Назад
Образовательные
- История
- Биология
- Физика
- Химия
- Русский язык
- Математика
- География
- ОБЖ
- Литература
- Английский язык
- Обществознание
- Медицина
- Другое
- Интеллектуальные
- Карьера и бизнес
- Развлекательные
- Для мужчин
- Для девушек
- Любовь и семья
- Для детей
- Здоровье
Популярные
Новые
Старые
Популярные
А-Я
Я-А
Pro
Узнать свой психологический возраст
Pro
Тест на склонность к шизофрении
Тест Айзенка EPQ-R: узнайте свой темперамент
Чернильные пятна Роршаха: все ли в порядке с вашей психикой?
Опросник суицидального риска
Экспресс-тест на самооценку
Pro
Большая пятерка. Пятифакторная модель личности
Пятифакторная модель личности
Тест «Куб в пустыне». Узнайте свой истинный характер!
Протестируй свою психику!
Черты характера – тест в картинках
Загрузить еще
Тесты на определение типа личности и характера всегда были особо популярными, благодаря своей эффективности и информативности. Среди них встречаются, как мощные профессиональные психологические тесты и методики, способные разглядеть в Вас самые потайные закоулки характера, так и простые быстрые «таймкиллеры», которые благодаря ассоциациям помогут обратить ваше внимание на нечто, что вы раньше не замечали. Здесь вы можете выбрать любые из множества тестов личности и характера, и пройти их онлайн абсолютно бесплатно.
Среди них встречаются, как мощные профессиональные психологические тесты и методики, способные разглядеть в Вас самые потайные закоулки характера, так и простые быстрые «таймкиллеры», которые благодаря ассоциациям помогут обратить ваше внимание на нечто, что вы раньше не замечали. Здесь вы можете выбрать любые из множества тестов личности и характера, и пройти их онлайн абсолютно бесплатно.
Тест на характер человека по теории Эрнста Кречмера
Черты характера очень тяжело поместить в одну небольшую классификацию. Они слишком ветвисты, зависят от обстоятельств, касаются разных сфер (отношение к себе, другим людям, вещам и т. п.). Поэтому Эрнст Кречмер решил сделать лишь обобщающее описание трех типов характера, которые основывал не только на психологии, но также на… физиологии. Интересно? Тогда пройдите этот тест на характер, и он покажет, к какому типу вы относитесь согласно теории немецкого психиатра.
1. На какой из этих типов ваша кожа похожа больше всего?
Жирная, быстро приобретает сальный блеск, есть склонность к акне, бывают отеки.
Сухая или комбинированная, часто шелушится, облазит. Легко остаются синяки, относительно хорошо видны сосуды.
Нормальная или комбинированная. Подтянутая и упругая. Есть здоровый блеск, виден румянец.
2. У вас свободный вечер. Чем из перечисленного вы бы предпочли заняться?
Читать, смотреть видео о науке, саморазвитии, бизнесе, искусстве.
Встретиться с друзьями или заняться готовкой.
Сделать разминку, потанцевать.
3. Часто ли новые знакомые принимают вас за безэмоционального, безразличного человека?
Часто.
Редко.
Никогда.
4. Друзья пригласили вас на большую вечеринку. Чем вы скорее всего будете там заниматься?
Активно общаться, знакомиться, шутить, есть угощения.
Предлагать свои игры, общаться с уже знакомыми людьми, делать то, чем занимается большинство.
Изучать интерьер, держаться в стороне, просматривать книги/журналы. Возможно, играть в настольную игру.
5. Часто ли вы болеете?
Нет.
Да, чаще это простуда или головные боли (мигрени).
Да, чаще это проблемы с желудком или сердцем.
6. Как часто вам говорят, что вы очень энергичны?
Часто/иногда, говоря о моей физической активности.
Часто/иногда, говоря о моем характере и эмоциях.
Практически никогда.
7. Вы увидели на улице очень милого бездомного котенка, но понимаете, что не можете забрать его домой. Ваша реакция?
Буду под огромным впечатлением, но вскоре отвлекусь.
Расстроюсь, скорее всего буду весь день вспоминать его грустные глаза.
Постараюсь найти ему хозяев, отдать в приют или куплю ему еды.
8. Вам чаще бывает тяжело выполнять даже короткие, но интенсивные физические тренировки?
Да, больше беспокоит слабость, головокружение или потемнение в глазах.
Да, больше беспокоит нехватка дыхания, одышка, боли в суставах или тошнота.
Нет или проблемы бывают нечасто.
9. Тяжело ли вам проявлять искренность и откровенность, общаясь с другими людьми?
Нет.
Да.
Иногда, с незнакомцами.
10. У вас наступил долгожданный отпуск и появилась возможность съездить куда-то. Что выберете?
Тур с экскурсиями, достопримечательностями.
Путевку на море.
Горнолыжный курорт или поход на природу.
11. Вам предложили работу в другом городе с неплохими финансовыми перспективами. Но вы понимаете, что, приняв предложение, вы окунетесь в совершенно новую, незнакомую вам ранее среду со своими сложностями. Что заставит вас использовать эту возможность?
Желание доказать всем, что вы можете добиться успеха.
Желание сменить обстановку.
Финансовые перспективы.
12. Какая у вас самооценка?
Заниженная.
Адекватная.
В целом адекватная, но порой бывает завышенной.
13. Занимаетесь ли вы спортом? Можно ли назвать ваше питание более-менее здоровым?
Спорт не люблю вообще. Мое питание могло бы быть гораздо более полезным.
Спортом почти не занимаюсь или делаю это редко. В целом образ питания можно назвать здоровым.
Занимаюсь. Стараюсь соблюдать здоровое питание.
Стараюсь соблюдать здоровое питание.
14. Вам представили нового знакомого, который почему-то вам сразу не понравился. Но так уж случилось, что вам придется часто видеться в одной компании. Как будете вести себя?
Постараюсь получше его узнать и проникнуться симпатией.
Проявлю вежливость, но неприязнь скорее всего останется.
Прямо дам понять человеку, что он мне не особо нравится либо стану игнорировать его.
15. Что большинство окружающих, по-вашему, думает или даже говорит о вашей фигуре?
Что у меня очень хорошая фигура и они сами хотели бы иметь такую.
Что я слишком худощав(а) и мне нужно набрать вес/мышечную массу.
Что мне нужно сбросить лишние килограммы.
16. Как обстоят дела с вашим давлением?
Бывает пониженным.
Почти всегда в норме.
Бывает повышенным.
17. Ваши два лучших друга ужасно поссорились. Как вы будете действовать дальше?
Постараюсь логически определить, кто прав, кто виноват, и справедливо рассудить их.
Продолжу общаться с каждым из них, а ссору пусть решают между собой сами.
Буду апеллировать к их чувствам и постараюсь помирить любым способом.
18. В чем вас чаще всего обвиняют окружающие?
В переменчивости, чрезмерной эмоциональности.
В нелюдимости, замкнутости, холодности, “заумности”.
В грубой прямолинейности, легкомыслии или эгоизме.
19. Как часто и легко ли вы меняете свое мнение о чем-либо?
Часто.
Зависит от конкретной ситуации.
Нечасто, меня вообще сложно переубедить.
20. Склонны ли вы подавлять свои эмоции или держать их в себе?
Я выражаю свои эмоции, но, как правило, сдержанно.
Нет, все мои эмоции практически сразу же видны.
Бывает/я не особо эмоциональный человек.
Разработка статистической викторины «Какой персонаж»
Эта страница служит руководством для статистической викторины «Какой персонаж» , а также для версии отчета коллег и пары.
Эта страница находится в разработке! Пожалуйста, зайдите как-нибудь для полированной версии!
Предыстория
Когда я, ваш автор, рассказывал людям, что я публикую личностные тесты в Интернете, меня часто спрашивали, означает ли это, что я работал на веб-сайт BuzzFeed, пишу их «Какой вы _________ персонаж?» викторины личности. И я должен был бы ответить, что нет, я больше интересуюсь наукой и человеческой природой, чем развлечением; эти викторины забавны, но не настолько значимы. И это не критика BuzzFeed! Ценность BuzzFeed (и всех других источников тестирования персонажей) подтверждается их популярностью. Это веселые игры. Людям нравится их принимать: дело закрыто. Однако, если вас интересует вопрос о том, как проводить хорошие психологические измерения, я полагаю, что они никогда не предлагали много интересного для размышлений. Я создал этот тест в 2019 году после того, как у меня появилась идея представить каждый символ в виде вектора, который можно заполнить краудсорсинговыми данными. И это на самом деле дало мне много интересных вещей для размышлений! Поэтому я немного отказываюсь от своего прежнего предубеждения против идеи характерной личности.
И я должен был бы ответить, что нет, я больше интересуюсь наукой и человеческой природой, чем развлечением; эти викторины забавны, но не настолько значимы. И это не критика BuzzFeed! Ценность BuzzFeed (и всех других источников тестирования персонажей) подтверждается их популярностью. Это веселые игры. Людям нравится их принимать: дело закрыто. Однако, если вас интересует вопрос о том, как проводить хорошие психологические измерения, я полагаю, что они никогда не предлагали много интересного для размышлений. Я создал этот тест в 2019 году после того, как у меня появилась идея представить каждый символ в виде вектора, который можно заполнить краудсорсинговыми данными. И это на самом деле дало мне много интересных вещей для размышлений! Поэтому я немного отказываюсь от своего прежнего предубеждения против идеи характерной личности.
Дополнительной целью этого проекта было создание набора данных, который можно было бы использовать в статистических исследованиях и образовании. Я думаю, что этот набор данных отлично подходит для обучения факторному анализу или алгоритмам кластеризации. Из-за этой дополнительной цели набор данных был разработан так, чтобы он был намного богаче, чем это было бы необходимо только для создания теста. Например, количество функций, по которым пользователи оценивают персонажей, намного больше и разнообразнее.
Я думаю, что этот набор данных отлично подходит для обучения факторному анализу или алгоритмам кластеризации. Из-за этой дополнительной цели набор данных был разработан так, чтобы он был намного богаче, чем это было бы необходимо только для создания теста. Например, количество функций, по которым пользователи оценивают персонажей, намного больше и разнообразнее.
Сбор рейтингов персонажей
Вместо того, чтобы создатель теста решал, каким должен быть профиль каждого персонажа, основываясь только на их мнении, мнения большого количества людей будут усредняться для создания профилей персонажей.
Был выбран формат 100-балльной шкалы, которая закреплена на каждом конце прилагательным.
Для начала набор тестовых данных был заполнен добровольцами из Reddit (начиная с персонажей «Игры престолов» и «Гарри Поттера»), но как только работоспособная версия теста была запущена, база данных стала самоподдерживающейся благодаря добровольцам, набранным из людей, принимавших участие в тестировании. контрольная работа. После того, как пользователь ответил на опрос личностного рейтинга, но до того, как он просмотрел свои результаты, его спрашивают, готовы ли они оценить некоторых персонажей. Уровень отказа составляет около 35%. Затем добровольцев просят выбрать любые вымышленные вселенные, о которых они знают, из списка, а затем персонажи из этой вселенной сопоставляются с элементами из набора функций (обычно случайным образом), и они оценивают их. После этого задается еще несколько вопросов об отношении пользователя к этой вымышленной вселенной и некоторые демографические вопросы. Их опрос, где оценивались персонажи, менялся со временем, но в основном выглядел так, как показано на скриншоте ниже.
контрольная работа. После того, как пользователь ответил на опрос личностного рейтинга, но до того, как он просмотрел свои результаты, его спрашивают, готовы ли они оценить некоторых персонажей. Уровень отказа составляет около 35%. Затем добровольцев просят выбрать любые вымышленные вселенные, о которых они знают, из списка, а затем персонажи из этой вселенной сопоставляются с элементами из набора функций (обычно случайным образом), и они оценивают их. После этого задается еще несколько вопросов об отношении пользователя к этой вымышленной вселенной и некоторые демографические вопросы. Их опрос, где оценивались персонажи, менялся со временем, но в основном выглядел так, как показано на скриншоте ниже.
Шкала идет от 1 (крайний левый) до 100 (крайний правый). Пользователь не получил инструкций по этому поводу в рейтинговом опросе, но во время основной части теста они использовали аналогичные шкалы ползунков для оценки себя, которые отображали числовые значения, и поэтому пользователь должен был установить связь и понять, что шкала была. Количество оценок, которые дал бы конкретный пользователь, менялось с течением времени. Первоначально пользователям было назначено 30 оценок, но это оказалось слишком много, поэтому в настоящее время пользователям назначено 15 оценок, если только для вселенной, где данные редки, им назначено 25.
Количество оценок, которые дал бы конкретный пользователь, менялось с течением времени. Первоначально пользователям было назначено 30 оценок, но это оказалось слишком много, поэтому в настоящее время пользователям назначено 15 оценок, если только для вселенной, где данные редки, им назначено 25.
После этого было задано несколько вопросов, которые должны помочь оценить отношение этого пользователя к работе, как показано ниже.
Затем, наконец, были заданы некоторые демографические вопросы, чтобы представить выборку в контексте, изображенном ниже.
Это была последняя страница опроса волонтеров, и после ее отправки пользователи сразу же получали результаты. Эта страница также собирала согласие на использование данных пользователя в качестве последнего вопроса. Данные пользователей, которые не ответят утвердительно на этот вопрос, удаляются.
С помощью этой процедуры было собрано очень большое количество рейтингов. На приведенном ниже графике показано количество завершенных опросов в день с момента преобразования этого опроса в текущий рабочий процесс.
С учетом того, что каждый пользователь поставил до 30 оценок в одном опросе, в общей сложности было сделано более 69 496 000 оценок, распределенных по 400 элементам для 1750 символов. Они были распределены несколько неравномерно, так как более известные вселенные получают больше оценок, но были приняты меры, чтобы каждый элемент для каждого персонажа в базе данных получил не менее 3.
Генерация биполярных шкал
Формат элемента для викторины и набора данных был выбран в виде шкалы от 1 до 100 с закрепленным текстом на обоих концах. Это не самый распространенный формат в психологических измерениях, на самом деле рейтинговые шкалы с ползунками имеют существенные проблемы, за которые я ранее их критиковал. Причина, по которой был выбран этот формат, связана с соображениями пользовательского опыта. Чтобы сделать работу викторины понятной для пользователей, на странице результатов должен быть график, а график лучше выглядит с высокой степенью детализации. Например, если бы ответы пользователей оценивались по шкале от 1 до 5, составленная из них точечная диаграмма выглядела бы очень неуклюжей.
Элементы были созданы вашим автором с течением времени, пока их не стало 400. Это гораздо больше элементов, чем реально может быть использовано в викторине. Тест из 400 вопросов был бы слишком длинным. Но наличие всех этих элементов позволяет нам оценивать и выбирать наиболее эффективные элементы. Это также делает набор данных более полезным для образовательных целей.
Один из способов оценить, насколько хорош предмет, насколько он хорош. И этот метод более или менее похож на то, как делаются другие тесты персонажей: создатель задает вопросы, которые им кажутся хорошими. Как объяснялось ранее, суждение многих лучше, чем суждение одного. Итак, эта проблема была краудсорсингом для тестирования пользователей в опросе, который выглядел следующим образом.
Этот опрос проводился до тех пор, пока не менее 500 человек не высказали свое мнение по каждому вопросу. Ниже приведены вопросы с наивысшим и наименьшим средним баллом (4 = определенно включены; 1 = определенно исключены).
Проверка достоверности оценок пользователей
Предпосылка этой викторины заключается в том, что объединение оценок различных пользователей повышает их точность, но это предположение, которое не может быть верным. Например, если личность персонажа полностью находится в глазах смотрящего и не имеет согласованности между разными оценщиками, то идея любого теста на определение личности персонажа бессмысленна. Этот вопрос известен как межэтническая надежность. Говорить о характере определенного типа будет иметь смысл только в том случае, если люди согласны с тем, что персонаж именно такой. Обычно это измеряется коэффициентом внутриклассовой корреляции (ICC1). Значение ICC варьируется от 0 до 1. Где 0 означает отсутствие согласия, а 1 — полное согласие. В таблице ниже представлены 10 вопросов с самой высокой и самой низкой межоценочной надежностью.
Некоторые вопросы были более надежными, чем другие. Некоторые вопросы имели очень низкую надежность, и, глядя на них, это имеет смысл.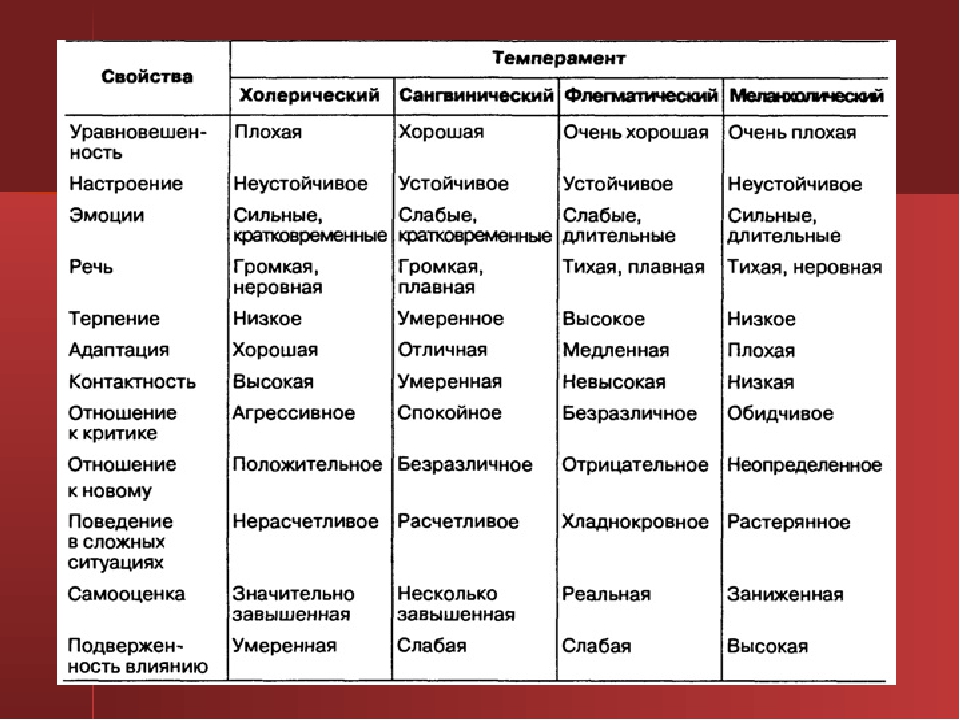 Все элементы с низкой надежностью кажутся немного запутанными. Вопрос, который показал самую низкую надежность, — это контраст между «правополушарным» и «левополушарным». Этот вопрос является отсылкой к поп-психологической идее личности о том, что люди предпочитают использовать одну сторону своего мозга и что каждая сторона имеет определенные функции. Низкая согласованность оценок по этому вопросу совпадает с моим предыдущим опытом работы с этой идеей. В свое время я попытался создать свою собственную меру левополушарного мозга по сравнению с правым полушарием и обнаружил, что это была в основном бессвязная/бессмысленная идея. Каждое определение того, что, по их мнению, значит быть левым или правым полушарием, слишком сильно различалось, чтобы вообще быть полезным. См. раздел «Разработка шкалы доминирования открытого полушария мозга».
Все элементы с низкой надежностью кажутся немного запутанными. Вопрос, который показал самую низкую надежность, — это контраст между «правополушарным» и «левополушарным». Этот вопрос является отсылкой к поп-психологической идее личности о том, что люди предпочитают использовать одну сторону своего мозга и что каждая сторона имеет определенные функции. Низкая согласованность оценок по этому вопросу совпадает с моим предыдущим опытом работы с этой идеей. В свое время я попытался создать свою собственную меру левополушарного мозга по сравнению с правым полушарием и обнаружил, что это была в основном бессвязная/бессмысленная идея. Каждое определение того, что, по их мнению, значит быть левым или правым полушарием, слишком сильно различалось, чтобы вообще быть полезным. См. раздел «Разработка шкалы доминирования открытого полушария мозга».
Мы можем построить график надежности каждого вопроса по сравнению со средней оценкой вопроса, полученного в опросе, где пользователей спрашивали, какие вопросы, по их мнению, следует использовать в викторине. Некоторые точки были помечены, чтобы помочь с интерпретацией.
Некоторые точки были помечены, чтобы помочь с интерпретацией.
Корреляция между ними была положительной, но умеренной (r=0,37). Глядя на отдельные точки, мы можем понять, почему это имеет смысл. Пользователи, как правило, могли сказать, какие вопросы бессмысленны, и соглашались, что их не следует использовать в тесте. Некоторые вопросы были исключениями, когда они были надежными, но по-прежнему получали низкое одобрение пользователей. Одним из них был пункт молодой (не старый) . Это второй самый надежный вопрос, но он получил очень низкие оценки пользователей. И в этом есть смысл, пользователи не любят этот вопрос, потому что он бессмысленный, они не любят его, потому что он не о личности. Итак, вы можете видеть, как это демонстрирует, что важно, чтобы вопрос был надежным, но надежности недостаточно.
Причины ненадежности
Моделирование рейтингов личности персонажа
Итак, у нас есть все эти рейтинги персонажей, и мы можем спросить: «Какая модель личности персонажа является лучшей?» Набор данных содержит 400 значений для каждого символа, но, возможно, некоторые из этих значений избыточны? Вероятно, вы могли бы хорошо описать символы с гораздо менее чем 400 значениями на символ. Типичный анализ для этого в психометрии называется факторным анализом. Факторный анализ пытается объяснить больший набор наблюдаемых значений меньшим набором фундаментальных причин.
Типичный анализ для этого в психометрии называется факторным анализом. Факторный анализ пытается объяснить больший набор наблюдаемых значений меньшим набором фундаментальных причин.
Когда вы запускаете факторный анализ, первое, на что вы смотрите, это «график осыпи». Факторный анализ извлекает факторы по одному, каждый раз пытаясь заставить извлеченный фактор выполнять как можно больше работы, поэтому каждый последующий фактор выполняет меньше работы, чем предыдущий. Вы можете посмотреть, какую дисперсию объясняет каждый фактор, а затем сделать вывод о том, насколько они важны. График осыпи, полученный в результате факторного анализа 400 значений для 1600 символов, приведен ниже.
Интерпретация сюжета осыпи — это больше искусство, чем наука, но я хочу сказать, что вижу 8 факторов, которые, похоже, работают здесь. Поэтому для остальной части анализа в этом разделе я буду рассматривать только первые 8 извлеченных факторов. Факторный анализ вычисляет нагрузку каждой переменной на каждый фактор. Нагрузка — это то, как анализ оценивает корреляцию этой переменной с фактором. Таким образом, мы можем посмотреть на переменные с наибольшей нагрузкой, чтобы попытаться интерпретировать, что представляет собой каждый фактор. В приведенной ниже таблице показаны нагрузки нескольких основных элементов, которые нагружают каждый фактор.
Нагрузка — это то, как анализ оценивает корреляцию этой переменной с фактором. Таким образом, мы можем посмотреть на переменные с наибольшей нагрузкой, чтобы попытаться интерпретировать, что представляет собой каждый фактор. В приведенной ниже таблице показаны нагрузки нескольких основных элементов, которые нагружают каждый фактор.
| Feature | Factor loading | |||||||||||||||
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | |||||||||
| cruel (not kind) | 0.97 | -0,01 | 0,07 | 0,06 | 0,01 | -0,01 | 0,03 | -0,01 | ||||||||
| Яизование (не нрат0071 | 0.05 | 0.02 | -0.01 | 0.07 | 0.02 | |||||||||||
| angelic (not demonic) | -0.95 | -0.17 | -0.09 | 0.02 | 0 | 0. 01 01 | -0.05 | -0.02 | ||||||||
| scheduled (not spontaneous) | 0.04 | -0.92 | 0.04 | 0.17 | -0.17 | 0.04 | 0 | 0.02 | ||||||||
| serious (not bold) | 0.01 | -0.9 | -0.07 | -0.02 | -0.09 | -0.06 | 0.24 | 0 | ||||||||
| orderly (not chaotic) | -0.28 | -0.87 | 0.18 | 0.21 | -0.06 | -0.05 | -0.05 | 0.01 | ||||||||
| noob (not pro) | 0.05 | 0.08 | -0.9 | -0.04 | 0.06 | 0 | -0.02 | -0.08 | ||||||||
| mighty (not puny) | -0.06 | -0.02 | 0.9 | 0.01 | 0.19 | 0.03 | 0.07 | -0.08 | ||||||||
| badass (not weakass) | -0. 15 15 | 0.15 | 0.89 | -0.07 | 0.09 | 0.03 | 0.04 | -0.01 | ||||||||
| scruffy (not manicured) | 0.02 | 0.31 | -0.04 | -0.86 | 0.04 | -0.07 | 0.12 | -0.01 | ||||||||
| blue-collar (not ivory-tower) | -0.31 | 0.05 | 0.01 | -0.83 | 0.16 | 0 | -0.02 | -0.03 | ||||||||
| proletariat (not bourgeoisie) | -0.4 | 0.09 | 0.05 | -0.82 | 0.02 | 0 | 0.05 | 0.02 | ||||||||
| sporty (not bookish) | 0.13 | 0.36 | 0.18 | -0.21 | 0.84 | -0.02 | -0.04 | -0.03 | ||||||||
| nerd (not jock ) | -0.27 | -0.22 | -0.3 | 0.06 | -0. 8 8 | 0.07 | -0.02 | 0.15 | ||||||||
| intellectual (not physical) | -0.14 | -0.39 | 0.1 | 0.27 | -0.79 | 0 | 0.03 | 0.14 | ||||||||
| leisurely (not hurried) | -0.07 | 0.45 | 0 | 0.01 | -0.01 | -0.77 | -0,18 | -0,1 | ||||||||
| сонный (не бешеный) | -0,29 | -0,24 | -0,25 | -0,16 | -0,25 | -0,16 | -0,25 | -0,16 | -0,25 | -0,16 | -0,25 | -0,16 | -0,25 | -0,16 | -0,25 | -0,16711170 -0,25 |
| aloof (not obsessed) | -0.38 | 0.1 | -0.04 | -0.11 | 0.16 | -0.67 | -0.08 | -0.08 | ||||||||
| sad (not happy) | 0. 53 53 | -0.23 | 0 | -0.1 | -0.04 | 0.05 | 0.76 | -0.01 | ||||||||
| cheery (not sorrowful) | -0.48 | 0.36 | -0.12 | 0.15 | 0.02 | -0.01 | -0.73 | 0.01 | ||||||||
| traumatized (not flourishing) | 0.38 | -0.02 | -0.26 | -0.26 | 0 | 0.16 | 0.68 | 0.02 | ||||||||
| luddite (not technophile) | 0.09 | 0.04 | -0.07 | -0.19 | 0.18 | -0.06 | 0 | -0.91 | ||||||||
| high-tech (not or low-tech ) | -0,02 | -0,07 | 0,23 | 0,29 | -0,19 | 0,1 | 0,01 | 0,86 | 0,01 | 0,86 | 0,01 | 0,86 | 0,01 | |||
 И это может быть своего рода и имеет смысл и кажется разумным. Однако я неравнодушен к фразе «факторный анализ
И это может быть своего рода и имеет смысл и кажется разумным. Однако я неравнодушен к фразе «факторный анализ Для персонажей, которых играют актеры (т. е. не анимационные и т. д.), актер, сыгравший этого персонажа, имеет измеримый рост, и можно сказать, что описание высокого и низкого роста (P69) напрямую связано с этим. Я взял рост актеров, указанный на Imdb, и сопоставил его с оценками их персонажей в нашем наборе данных:
Для персонажей, которых играют актеры (т. е. не анимационные и т. д.), актер, сыгравший этого персонажа, имеет измеримый рост, и можно сказать, что описание высокого и низкого роста (P69) напрямую связано с этим. Я взял рост актеров, указанный на Imdb, и сопоставил его с оценками их персонажей в нашем наборе данных: Выгода от добавления дополнительных рейтингов вначале очень велика, но после того, как персонажи набрали 10 рейтингов за черту, маржинальная выгода от еще одного рейтинга становится очень маленькой.
Выгода от добавления дополнительных рейтингов вначале очень велика, но после того, как персонажи набрали 10 рейтингов за черту, маржинальная выгода от еще одного рейтинга становится очень маленькой. CelebWikiBiography.com говорит: «Ее рост 5 футов 2 дюйма или 5 футов 4 дюйма или 5 футов 5 дюймов». в «Девочках». Рост Данхэм указан на IMDb как 5 футов 3 дюйма, что на дюйм выше, чем у Джемаймы Кирк! Но по нашим данным, Ханна Хороват получает 15,6/100 для высокого роста по сравнению с 67,2/100 для Джессы Йоханссон. Если мы посмотрим на их фотографии рядом, Кирк (синий) выглядит немного выше, чем Данхэм (красный).
CelebWikiBiography.com говорит: «Ее рост 5 футов 2 дюйма или 5 футов 4 дюйма или 5 футов 5 дюймов». в «Девочках». Рост Данхэм указан на IMDb как 5 футов 3 дюйма, что на дюйм выше, чем у Джемаймы Кирк! Но по нашим данным, Ханна Хороват получает 15,6/100 для высокого роста по сравнению с 67,2/100 для Джессы Йоханссон. Если мы посмотрим на их фотографии рядом, Кирк (синий) выглядит немного выше, чем Данхэм (красный). Это будет самая сложная философская проблема для этой системы сопоставления символов. Инвариантность измерения — это когда то, что кажется одной и той же мерой (здесь — один и тот же вопрос), дает ответы, которые имеют разное значение при использовании в разных группах населения или в разных контекстах. Например, при оценке роста низкорослых персонажей возникает проблема инвариантности измерений относительно пола персонажа. Посмотрите на тот же график, который мы видели раньше, с разбивкой по полу:
Это будет самая сложная философская проблема для этой системы сопоставления символов. Инвариантность измерения — это когда то, что кажется одной и той же мерой (здесь — один и тот же вопрос), дает ответы, которые имеют разное значение при использовании в разных группах населения или в разных контекстах. Например, при оценке роста низкорослых персонажей возникает проблема инвариантности измерений относительно пола персонажа. Посмотрите на тот же график, который мы видели раньше, с разбивкой по полу: .
. Затем им показывали случайный набор персонажей из этих вселенных и просили оценить, насколько каждый из них похож на них по шестибалльной шкале от 1 = Чрезвычайно похож до 6 = Чрезвычайно отличается (они также могли пропустить персонажа, если не знали) .
Затем им показывали случайный набор персонажей из этих вселенных и просили оценить, насколько каждый из них похож на них по шестибалльной шкале от 1 = Чрезвычайно похож до 6 = Чрезвычайно отличается (они также могли пропустить персонажа, если не знали) . Баллы в версиях теста с большим количеством вопросов, как правило, ниже для наиболее подходящего символа, чем в версиях с меньшим количеством вопросов. Чем больше у вас критериев, тем сложнее найти идеальное соответствие.
Баллы в версиях теста с большим количеством вопросов, как правило, ниже для наиболее подходящего символа, чем в версиях с меньшим количеством вопросов. Чем больше у вас критериев, тем сложнее найти идеальное соответствие. Обычный формат заключается в том, что кто-то составляет таблицу персонажей из вымышленной вселенной и выбирает по одному примеру, который, по его мнению, подходит для каждого из 16 типов. Обычно это выглядит как мем ниже, который показывает набор символов «Звездных войн» (от Entertainment Earth News):
Обычный формат заключается в том, что кто-то составляет таблицу персонажей из вымышленной вселенной и выбирает по одному примеру, который, по его мнению, подходит для каждого из 16 типов. Обычно это выглядит как мем ниже, который показывает набор символов «Звездных войн» (от Entertainment Earth News): Из 1600 профилей символов в наборе данных SWCPQ1.0 1537 имеют совпадающие профили в PDB.
Из 1600 профилей символов в наборе данных SWCPQ1.0 1537 имеют совпадающие профили в PDB. Люди, которые идентифицировали себя как ENFP, чаще всего говорили, что они похожи на Анну, а люди, которые идентифицировали себя как ESTJ, чаще всего говорили, что они похожи на Гермиону Грейнджер. И если мы обратимся к базе данных личностей, мы увидим, что это именно те типы, за которых люди голосовали за Анну и Гермиону! Итак, доказывает ли это, что типы Майерс-Бриггс законны? Моя позиция такова, что теория типов Майерс-Бриггс/юнгианская психология — это лженаука, но 16 типов могут использоваться как прилагательные, и описание вещей с помощью прилагательных — это разумный поступок. Действительно, Фрэнсис Гальтон насчитал в словаре более тысячи слов, которые можно использовать для описания людей, и мы можем сказать, что Майерс и Бриггс добавили еще 16. Они спрашивают, насколько полезны эти прилагательные, какую работу они выполняют?
Люди, которые идентифицировали себя как ENFP, чаще всего говорили, что они похожи на Анну, а люди, которые идентифицировали себя как ESTJ, чаще всего говорили, что они похожи на Гермиону Грейнджер. И если мы обратимся к базе данных личностей, мы увидим, что это именно те типы, за которых люди голосовали за Анну и Гермиону! Итак, доказывает ли это, что типы Майерс-Бриггс законны? Моя позиция такова, что теория типов Майерс-Бриггс/юнгианская психология — это лженаука, но 16 типов могут использоваться как прилагательные, и описание вещей с помощью прилагательных — это разумный поступок. Действительно, Фрэнсис Гальтон насчитал в словаре более тысячи слов, которые можно использовать для описания людей, и мы можем сказать, что Майерс и Бриггс добавили еще 16. Они спрашивают, насколько полезны эти прилагательные, какую работу они выполняют?
 Вернитесь назад и посмотрите на график того, насколько хорошо результаты совпадения из этой анкеты предсказывают, будет ли пользователь оценивать персонажа как похожего на себя: когда пользователь сопоставил персонаж на самом низком уровне, вероятность была менее 10%. они будут думать, что персонаж похож на них, по сравнению с вероятностью 80%, когда совпадающий балл был на высоком уровне.
Вернитесь назад и посмотрите на график того, насколько хорошо результаты совпадения из этой анкеты предсказывают, будет ли пользователь оценивать персонажа как похожего на себя: когда пользователь сопоставил персонаж на самом низком уровне, вероятность была менее 10%. они будут думать, что персонаж похож на них, по сравнению с вероятностью 80%, когда совпадающий балл был на высоком уровне. Но многие люди в Интернете предположили, что поиск персонажей того же типа, что и у вас, имеет большое значение. Я бы указал на это как на еще один пример распространенного явления, когда люди сильно переоценивают полезность категоризации по типам Майерс-Бриггс.
Но многие люди в Интернете предположили, что поиск персонажей того же типа, что и у вас, имеет большое значение. Я бы указал на это как на еще один пример распространенного явления, когда люди сильно переоценивают полезность категоризации по типам Майерс-Бриггс. ветку на r/SampleSize). Это говорит о том, что викторина на этом веб-сайте имеет лучшую процедуру сопоставления, хотя n = 15 слишком мало для меня, чтобы делать какие-либо супер конкретные заявления.
ветку на r/SampleSize). Это говорит о том, что викторина на этом веб-сайте имеет лучшую процедуру сопоставления, хотя n = 15 слишком мало для меня, чтобы делать какие-либо супер конкретные заявления.



